
Bloom Filter
Bloom Filter
Bài toán gốc rễ
Hãy tưởng tượng mày là kỹ sư tại Google. Hệ thống có 2 tỷ tài khoản Gmail. Mỗi ngày có hàng triệu người thử đăng ký. Với mỗi request, mày cần trả lời một câu hỏi duy nhất:
"Email này đã có ai dùng chưa?"
Nghe đơn giản. Nhưng scale mới là vấn đề.
Approach 1 — Query thẳng vào Database
Cách naive nhất: SELECT 1 FROM users WHERE email = ?. Với 2 tỷ record, mỗi query dù có index cũng mất vài milliseconds, cộng network latency. Hàng triệu request/ngày → database trở thành bottleneck ngay.
DB I/O tốn kém. Disk seek, buffer pool, network round-trip — tất cả cộng lại. Không scale được.
Approach 2 — Cache toàn bộ email vào RAM
Dùng Redis/Memcached lưu tất cả email vào memory. Nhanh hơn nhiều. Nhưng 2 tỷ email, trung bình 25 bytes/email → ~50 GB RAM chỉ để lưu email. Tốn tiền, không thực tế.
Memory không vô hạn. Dataset tăng tuyến tính → chi phí RAM tăng tuyến tính.
Approach 3 — Bloom Filter
Cùng 2 tỷ email, false positive rate 1% → chỉ tốn ~2.4 GB RAM. Nhanh hơn 20x so với Redis lookup thông thường. Đây chính là vấn đề Bloom Filter sinh ra để giải quyết.
Bloom Filter không lưu dữ liệu thực. Nó chỉ lưu dấu vết của dữ liệu dưới dạng bit — đánh đổi một tỉ lệ sai số nhỏ để tiết kiệm bộ nhớ cực lớn.
Cơ chế hoạt động
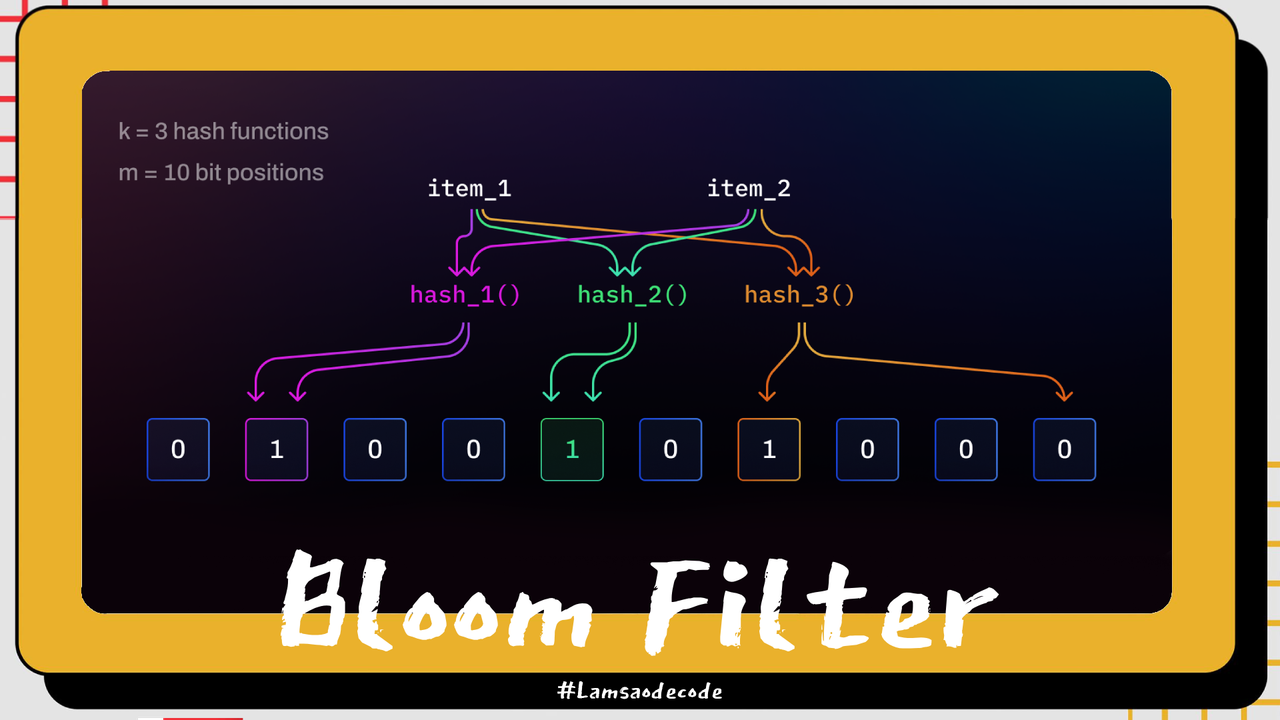
Bloom Filter là một bit array kích thước m, kết hợp với k hash functions độc lập. Ban đầu tất cả các bit đều là 0.
INSERT — Thêm một phần tử
Khi insert item x vào filter:
- Tính
khash values:h₁(x), h₂(x), ..., hₖ(x) - Mỗi hash value map sang một vị trí trong bit array (mod m)
- Set tất cả
kbit tương ứng lên1
// Insert "hello"
h1("hello") = 3 → set bit[3] = 1
h2("hello") = 7 → set bit[7] = 1
h3("hello") = 12 → set bit[12] = 1
// Insert "world"
h1("world") = 5 → set bit[5] = 1
h2("world") = 7 → bit[7] đã = 1, không sao
h3("world") = 9 → set bit[9] = 1QUERY — Kiểm tra sự tồn tại
Khi query item x:
- Tính tương tự
khash values - Kiểm tra tất cả
kbit tương ứng - Nếu bất kỳ bit nào = 0 → Definitely NOT in set
- Nếu tất cả bit đều = 1 → Probably in set
Khi ta insert x, ta set một số bit lên 1. Những bit đó không bao giờ bị reset về 0. Nên nếu x đã được insert, tất cả k bit của nó đều là 1 — guarantee 100%. Nếu bất kỳ bit nào là 0 thì chắc chắn x chưa được insert.
Tại sao có false positive?
Xét item y chưa được insert. Nhưng qua quá trình insert nhiều items khác, các bit mà h₁(y), h₂(y), h₃(y) trỏ tới đã vô tình bị set bởi những items khác nhau. Bloom Filter không thể phân biệt — nó chỉ thấy "tất cả bit = 1" và trả về "probably yes".
Toán học đằng sau
Bloom Filter có nền tảng toán học rất đẹp. Hiểu được sẽ giúp ích lớn trong phỏng vấn system design.
Xác suất false positive
Cho m bits, k hash functions, n items đã insert. Xác suất false positive:
Số hash functions tối ưu
Tính số bits cần thiết
Muốn lưu n items với false positive rate p:
Bảng sizing thực tế
| n (items) | FPR target | Memory | k |
|---|---|---|---|
| 1,000,000 | 1% | ~1.2 MB | 7 |
| 1,000,000 | 0.1% | ~1.8 MB | 10 |
| 1,000,000,000 | 1% | ~1.2 GB | 7 |
| 2,000,000,000 | 1% | ~2.4 GB | 7 |
2 tỷ email (~25 bytes/email) trong HashSet → ~50 GB. Trong Bloom Filter FPR 1% → chỉ ~2.4 GB. Tiết kiệm hơn 20 lần.
Interactive Demo
Thử tự tay insert và query để hiểu cơ chế hoạt động. Khi bit array đầy dần, tỉ lệ false positive sẽ tăng lên — mày sẽ thấy rõ điều này.
💡 Gợi ý: Insert ~10 từ rồi thử check một từ chưa insert — mày sẽ thấy false positive xảy ra khi nhiều bit bị set.
False Positive thực sự là gì?
Đây là phần nhiều người hiểu nhầm nhất. False positive trong Bloom Filter không phải bug — nó là trade-off có thể kiểm soát.
Nếu bất kỳ bit nào trong k bit của item là 0, item này chắc chắn chưa được insert. Không bao giờ sai. Đây là guarantee mạnh nhất của Bloom Filter.
Nếu tất cả k bit đều là 1, item có thể đã được insert — nhưng cũng có thể các bit đó bị set bởi những items khác. Xác suất sai này là false positive rate, thường set ở 1%.
Hệ quả thực tế
Trong production, khi Bloom Filter trả về "probably yes", mày vẫn phải verify với DB. Bloom Filter không thay thế DB — nó là tầng lọc đầu tiên để tránh những lookup DB chắc chắn không cần thiết.
| Kết quả | Ý nghĩa | Hành động |
|---|---|---|
| Filter: NOT found | Chắc chắn không tồn tại | Return ngay, không query DB |
| Filter: FOUND | Có thể tồn tại (hoặc false positive) | Query DB để confirm |
Với FPR = 1%, chỉ 1% request bị false positive và phải query DB không cần thiết. 99% request còn lại được fast-reject không tốn I/O.
Trade-off và khi nào dùng
| Ưu điểm | Nhược điểm |
|---|---|
| Memory cực nhỏ (vài GB cho hàng tỷ items) | Có false positive rate |
| O(k) time — constant, cực nhanh | Không thể delete item (standard) |
| No false negative — guarantee mạnh | Không retrieve được item gốc |
| Cache-friendly, CPU-efficient | FPR tăng khi dataset vượt dự kiến |
Dataset rất lớn (hàng triệu+), câu hỏi là có/không, chấp nhận false positive nhỏ, không cần delete thường xuyên, muốn fast-reject trước khi hit expensive resource (DB, disk, network).
Cần 100% accuracy (tài chính, y tế), cần delete items thường xuyên, dataset nhỏ (HashSet đủ rồi), cần retrieve giá trị thực của item.
Ứng dụng thực tế
RocksDB / Cassandra / LevelDB
Bloom Filter per SSTable. Trước khi đọc disk, hỏi filter. "Not found" → skip hoàn toàn. Giảm disk I/O hàng chục lần.
Chrome Safe Browsing
Lưu danh sách URL độc hại locally. "Clean" → không gọi server. "Maybe bad" → verify với Google API.
Gmail / Google Accounts
Check email đã đăng ký chưa khi tạo tài khoản. Filter fast-reject trước khi query DB chứa hàng tỷ accounts.
Web Crawlers
Đã crawl URL này chưa? Hàng tỷ URL không thể HashSet hết vào RAM. Bloom Filter nhớ dấu vết với memory cực nhỏ.
YouTube / Netflix
User đã xem video này chưa? Số cặp (user, video) lên hàng nghìn tỷ. Tránh recommend nội dung đã xem.
Akamai CDN
Track "lần đầu tiên thấy URL". Chỉ cache vào memory nếu đã thấy lần 2 — tránh cache one-hit wonders.
Redis RedisBloom
Module chính thức. Dùng để chặn spam, rate limiting theo IP/email mà không cần lưu toàn bộ danh sách.
Have I Been Pwned
Check password có trong danh sách 500M+ leaked passwords. Dataset quá lớn để HashSet — Bloom Filter là obvious choice.
Các biến thể của Bloom Filter
Implement từ scratch
TypeScript
class BloomFilter {
private bits: Uint8Array;
private m: number;
private k: number;
private count = 0;
constructor(expectedItems: number, fpr: number) {
// m = -n * ln(p) / (ln2)²
this.m = Math.ceil(
-expectedItems * Math.log(fpr) / (Math.LN2 ** 2)
);
// k = (m/n) * ln2
this.k = Math.ceil((this.m / expectedItems) * Math.LN2);
this.bits = new Uint8Array(Math.ceil(this.m / 8));
}
add(item: string): void {
for (const pos of this.positions(item)) {
this.bits[Math.floor(pos / 8)] |= (1 << (pos % 8));
}
this.count++;
}
has(item: string): boolean {
return this.positions(item).every(pos =>
((this.bits[Math.floor(pos / 8)] >> (pos % 8)) & 1) === 1
);
}
private positions(item: string): number[] {
// Double hashing: h(i) = h1(x) + i * h2(x)
let h1 = 5381, h2 = 52711;
for (const c of item) {
const code = c.charCodeAt(0);
h1 = ((h1 << 5) + h1) ^ code;
h2 = ((h2 << 5) - h2) ^ code;
}
return Array.from({length: this.k}, (_, i) =>
Math.abs((h1 + i * h2) >>> 0) % this.m
);
}
estimatedFPR(): number {
return (1 - Math.exp(-this.k * this.count / this.m)) ** this.k;
}
}
// Usage
const filter = new BloomFilter(1_000_000, 0.01); // 1M items, FPR 1%
filter.add("user@gmail.com");
filter.has("user@gmail.com"); // probably true
filter.has("other@gmail.com"); // definitely false OR ~1% false positiveGo
package bloom
import (
"math"
"encoding/binary"
"crypto/sha256"
)
type BloomFilter struct {
bits []byte
m, k uint
}
func New(n uint, fpr float64) *BloomFilter {
m := uint(-float64(n) * math.Log(fpr) / math.Ln2 / math.Ln2)
k := uint(float64(m) / float64(n) * math.Ln2)
return &BloomFilter{bits: make([]byte, (m+7)/8), m: m, k: k}
}
func (bf *BloomFilter) Add(item []byte) {
h1, h2 := bf.hashes(item)
for i := uint(0); i < bf.k; i++ {
pos := (h1 + i*h2) % bf.m
bf.bits[pos/8] |= 1 << (pos % 8)
}
}
func (bf *BloomFilter) Has(item []byte) bool {
h1, h2 := bf.hashes(item)
for i := uint(0); i < bf.k; i++ {
pos := (h1 + i*h2) % bf.m
if bf.bits[pos/8] & (1 << (pos % 8)) == 0 {
return false
}
}
return true
}
func (bf *BloomFilter) hashes(data []byte) (uint, uint) {
h := sha256.Sum256(data)
return uint(binary.BigEndian.Uint64(h[:8])),
uint(binary.BigEndian.Uint64(h[8:16]))
}Bloom Filter trong phỏng vấn
Bloom Filter là một trong những câu trả lời gây "wow effect" tốt nhất trong system design interview vì ít người junior nghĩ tới.
Pattern nhận diện — khi nào mention
Dataset rất lớn (triệu+) · Câu hỏi có/không · Muốn fast-reject trước khi tốn I/O · Chấp nhận sai số nhỏ. Thấy đủ 3 dấu hiệu này → propose Bloom Filter ngay.
Các bài system design hay trigger
Design Gmail registration
Email đã tồn tại chưa? → Bloom Filter fast-reject trước DB.
Design URL shortener
Short code đã tồn tại? → Filter trước INSERT.
Design web crawler
URL đã crawl chưa? → Tỷ URL, chỉ Bloom Filter mới vừa RAM.
Design key-value store
Key có trong SSTable không? → Per-SSTable Bloom Filter.
Design recommendation
User đã xem chưa? → Hàng nghìn tỷ cặp user-item.
Design spam filter
IP/email trong blacklist? → Local filter, không cần call DB mỗi request.
Follow-up questions phải biết
"FPR bao nhiêu là acceptable?" — Tuỳ context. Email registration: 0.1–1% ổn vì vẫn verify với DB. Spam filter: có thể chấp nhận 5%.
"User xoá account thì filter làm gì?" — Standard filter không shrink. Giải pháp: Counting BF, hoặc rebuild định kỳ (daily/weekly).
"Multi-node thì sync filter kiểu gì?" — Mỗi node giữ bản local, accept eventual consistency ngắn. Khi cần consistent mạnh: shared Redis BloomFilter.
"Cuckoo Filter khác gì?" — Hỗ trợ delete, lookup nhanh hơn một chút nhờ cache locality tốt hơn.
Đăng nhận xét